![Mendel’s Genetics [6]: Examples of epistasis](https://apbiology.cn/wp-content/uploads/sites/8/2013/12/genetics-3-snapdragons.jpg)
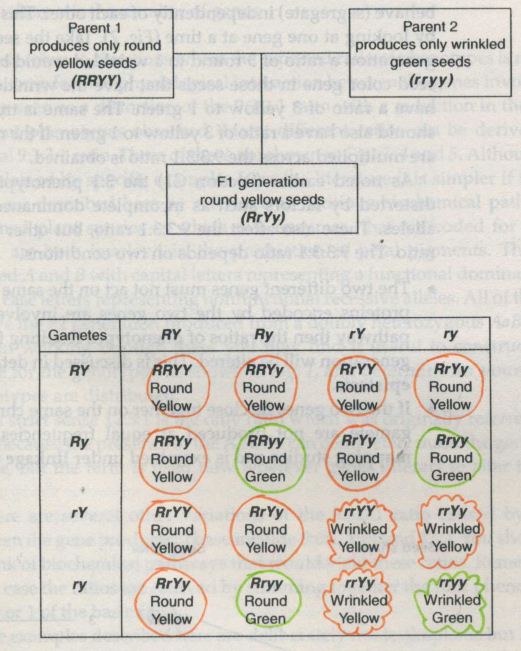
In Mendel’s dihybrid cross, each gene locus(the position of a gene along a chromosome, often used to refer to the gene itself.) had an independent effect on a single phenotype. Thus, the R and r alleles affected only the shape of the seed and had no influence on seed color, while the Y and y alleles affected only seed color and had no influence on seed shape. In this case, there were two separate genes that coded for two separate characteristics.But what happens when two different loci affect the same characteristic? For instance, what if both of the loci in Mendel’s experiment affected seed color?
Let’s begin with a relatively simple example.
- example (1) 9:3:3:1→9:7
enzyme A serves to convert white substrate in an unnamed plant to white product; enzyme B synthesizes purple pigment and converts the white product to purple product.
In this case, If BOTH A & B exist, purple product is yielded;
If ONLY A OR B exists, synthesis of purple pigment cannot be completed, and purple product won’t be produced;
If NEITHER ENZYME exist, purple pigment, surely, cannot be synthesized, and purple product won’t be produced.
Based on the info above, the dihybrid F2 generation looks like this:
When the situation gets a little bit more complicated:
- example (2) 9:3:3:1→9:3:4
enzyme A serves in the synthesis of red pigment and converts white substrate in an unnamed plant to red product; enzyme B synthesizes purple pigment and converts the red product to purple product.
In this case, If BOTH A & B exist, purple product is yielded;
If ONLY A exists, synthesis of red pigment can be completed but synthesis of purple pigment cannot, and red product will be produced;
If NEITHER ENZYME exist or ONLY B exists, surely, neither red or purple pigment, can be synthesized, and the the yield will be white.
Based on the info above, the dihybrid F2 generation looks like this:
A more complex situation:
- example (3): 9:3:3:1→12:3:1
Here two enzymes compete for the same substrate. Enzyme A converts the substrate to a purple product, and enzyme B to a red product. BUT enzyme A has much higher affinity for the substrate than enzyme B. The difference in affinity is so marked that enzyme B can only work effectively without the presence of enzyme A
SO as long as enzyme A is present, the yield is be purple; only when enzyme B exists without enzyme A would the yield be red; and only when neither B or A exists would the yield be white.
Based on the info above, the dihybrid F2 generation looks like this:
[F2] purple: red: white=12: 3: 1
The three examples above lead us to a new concept: Epistasis.
Sometimes genes can mask each other’s presence or combine to produce an entirely new trait. Epistasis describes how gene interactions can affect phenotypes.
In a strict sense, 12: 3: 1 is the only ratio which was originally referred to as epistasis, because the presence of enzyme A can completely make the genotype of the B gene. But the term is now used wherever genes interact to alter the expected ratios.
There are several other variations of the 9:3:3:1 ratio caused by interaction between the gene products, including 9:6:1, 15:1, and 13:3.
In every case the ratios are derived by summing together the four phenotype classes 9, 3, 3, or 1 of the basic ratio.
====================================================
For more examples and explanations of the Epistasis, see Epistasis and Its Effects on Phenotype | Learn Science at Scitable
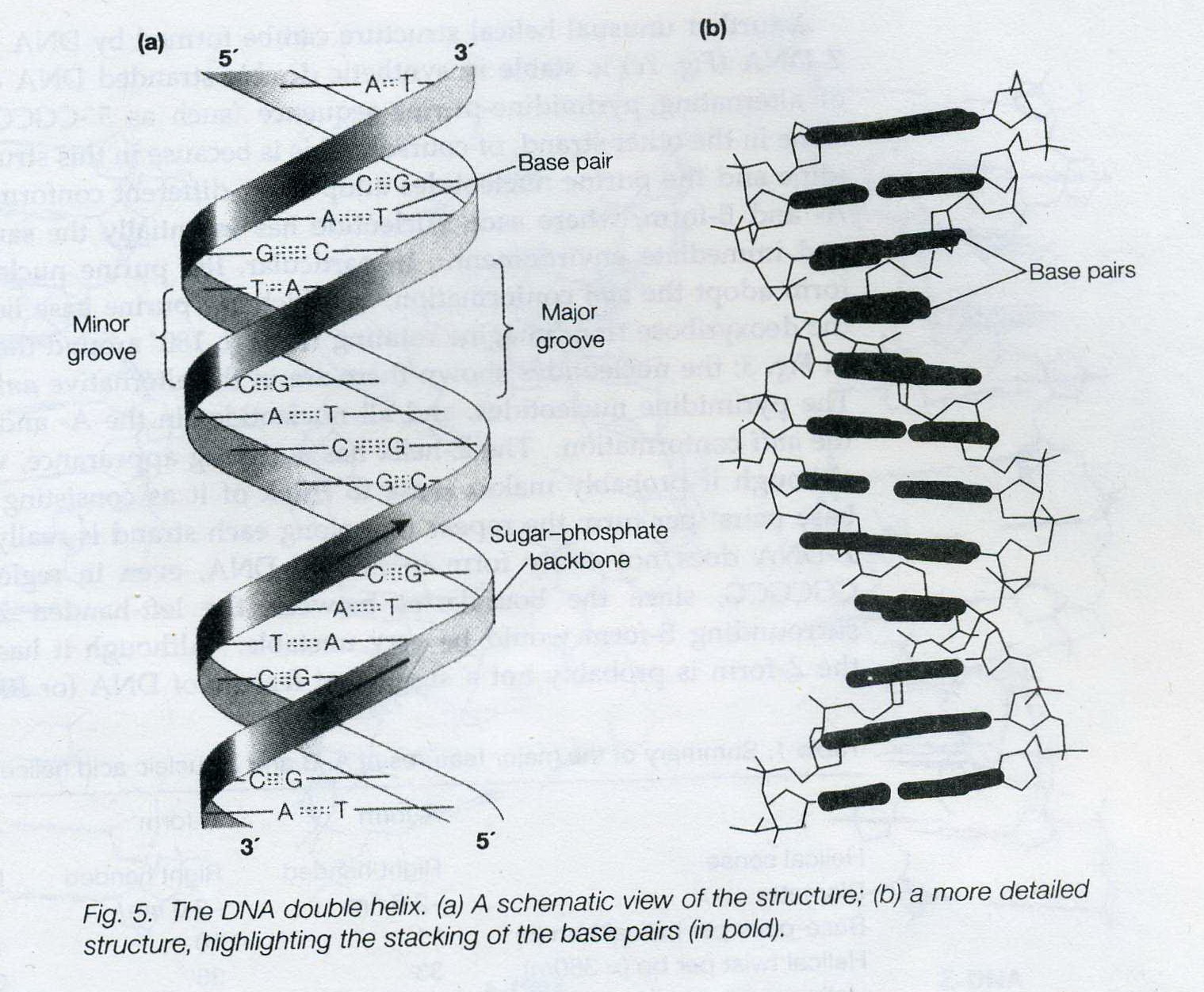
![The blueprint of life [5]: spectroscopic and thermal properties of DNA](https://apbiology.cn/wp-content/uploads/sites/8/2013/07/UV-absorption-of-DNA.jpg)
![Mendel’s Genetics [5]: The dihybrid cross](https://apbiology.cn/wp-content/uploads/sites/8/2013/07/genetics2.png)
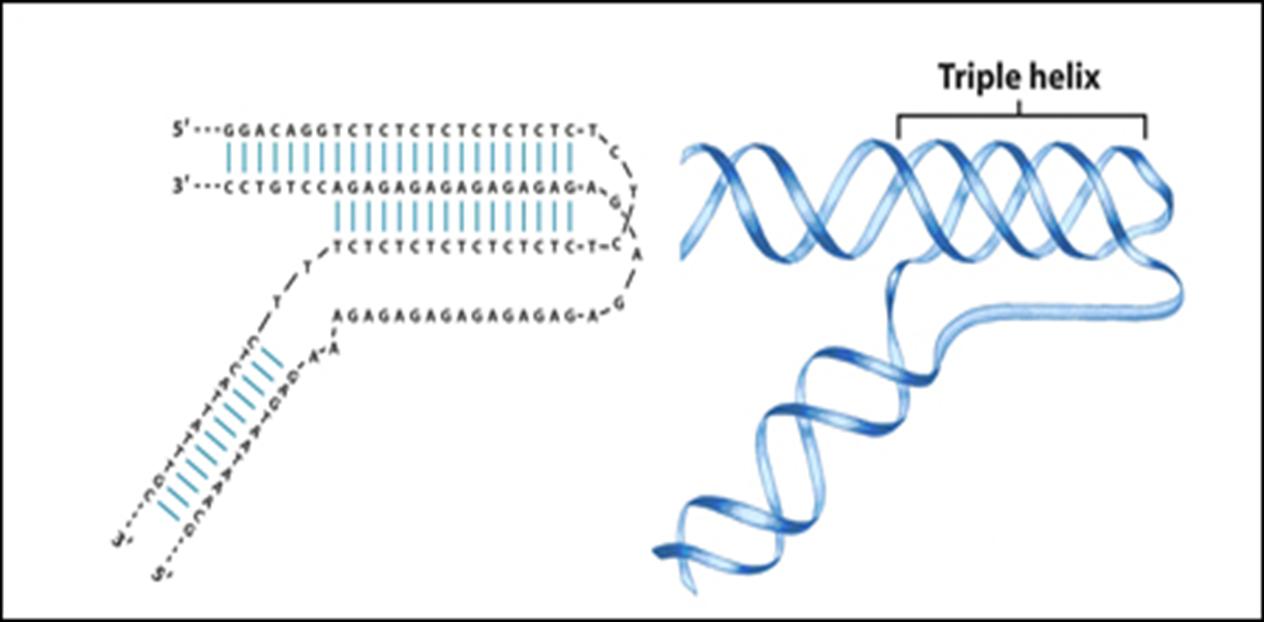
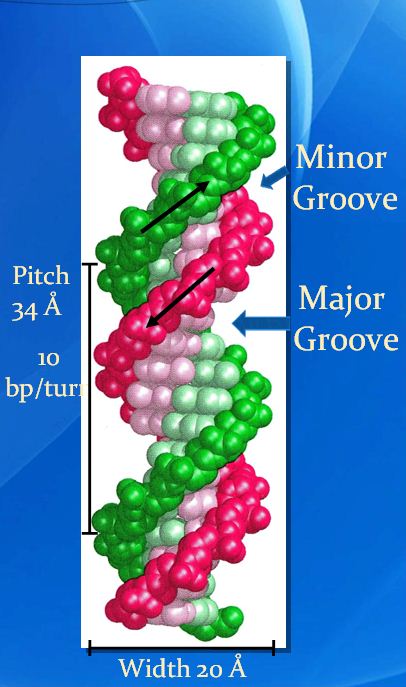
![The blueprint of life [4]: Tertiary Structure of DNA](https://apbiology.cn/wp-content/uploads/sites/8/2013/07/DNA-topology2.jpg)
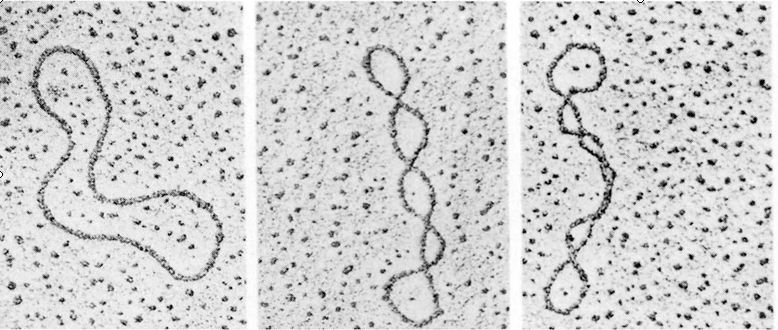
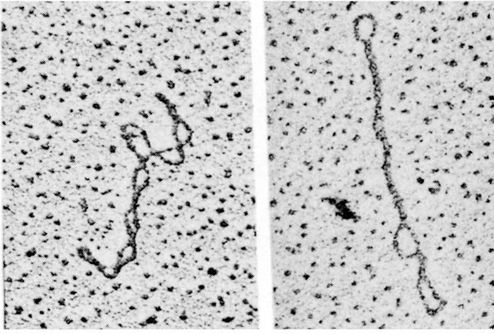
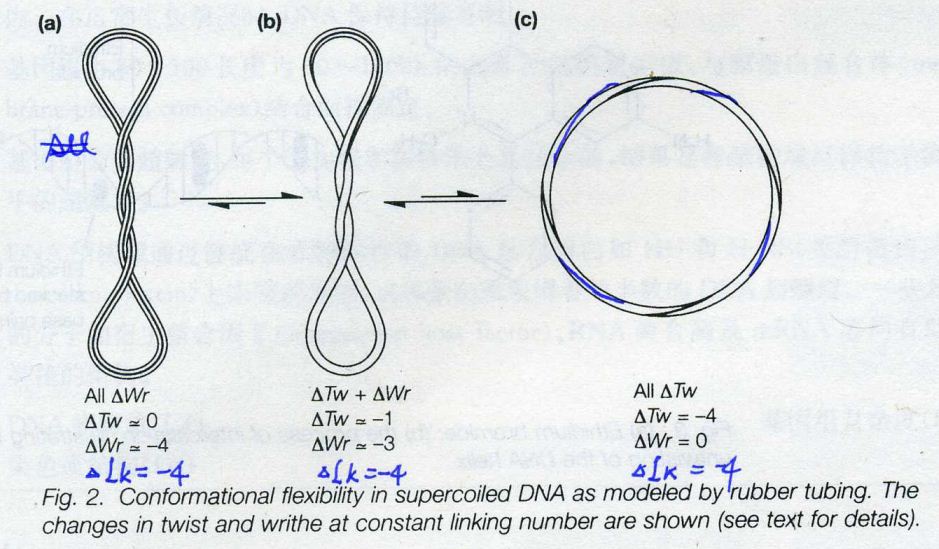
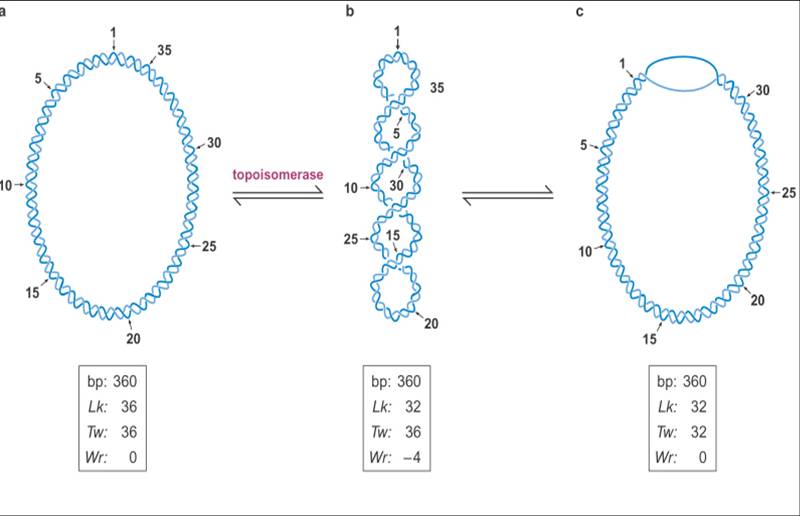

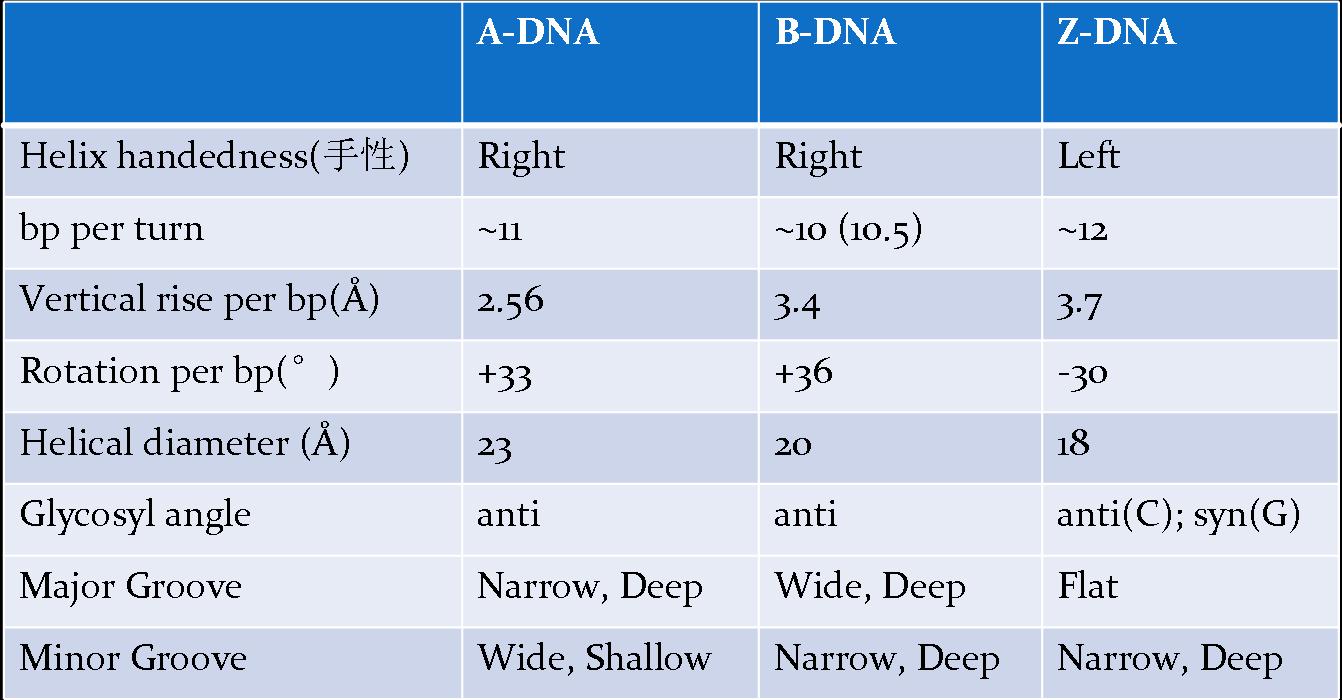
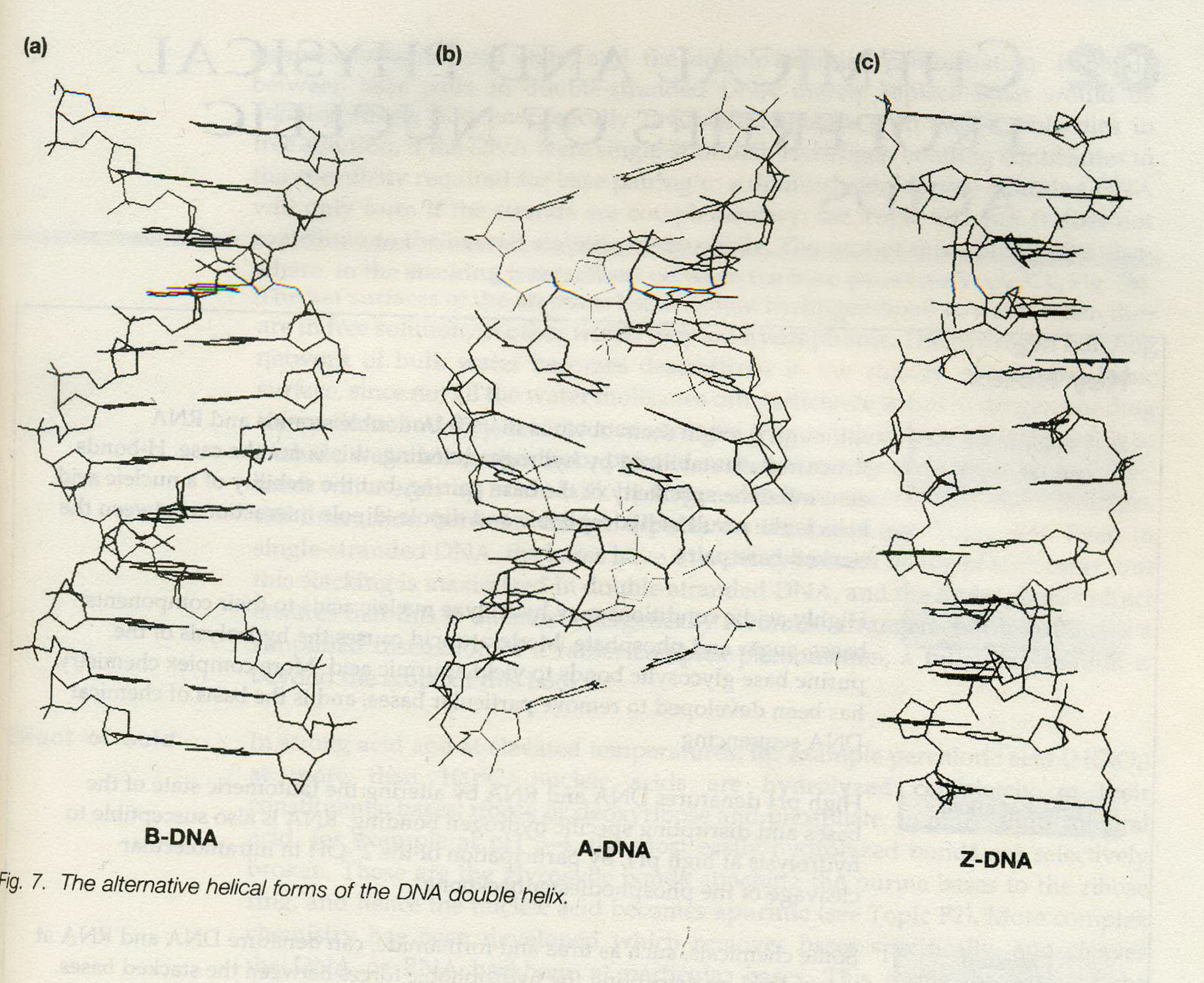
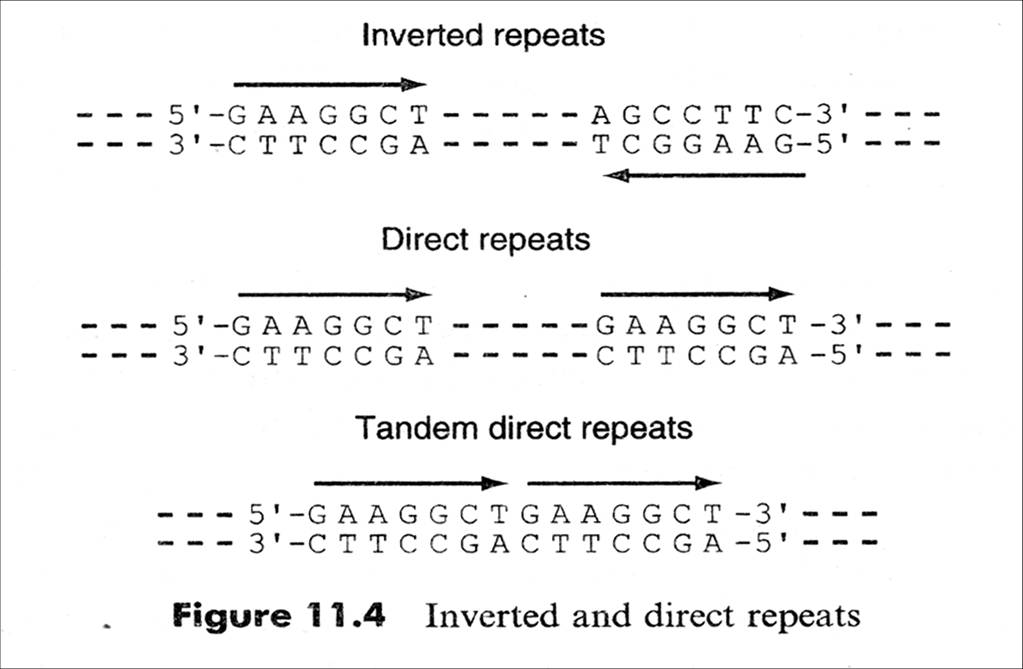
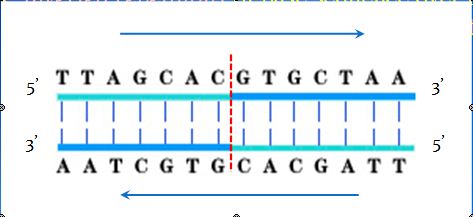
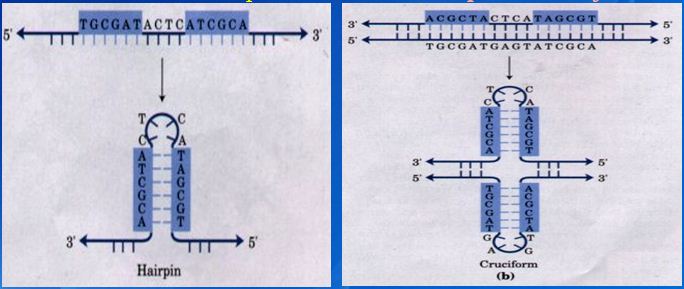
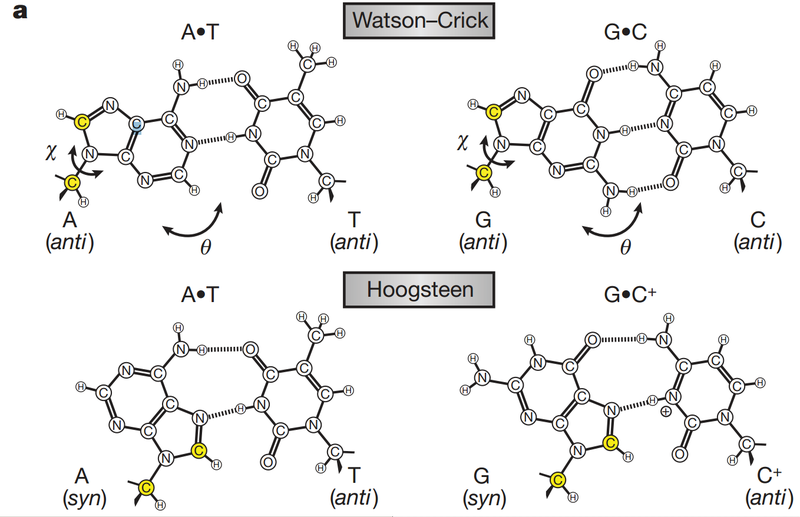
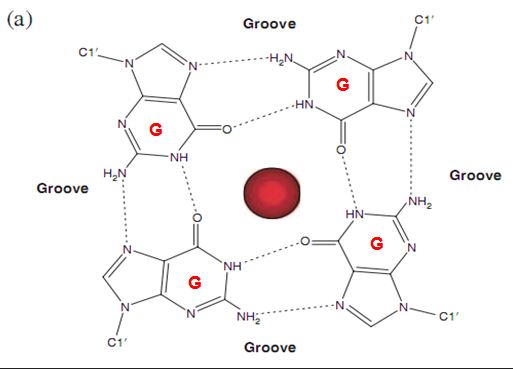
![The blueprint of life [3] secondary and some special structures of DNA](https://apbiology.cn/wp-content/uploads/sites/8/2013/07/dna2.jpg)